Pandas 层次化索引
层次化索引(Hierarchical / Multi-level Indexing)是pandas的一项重要功能,它使你能在一个轴上拥有多个(两个以上)索引级别。抽象点说,它使你能以低维度形式处理高维度数据。
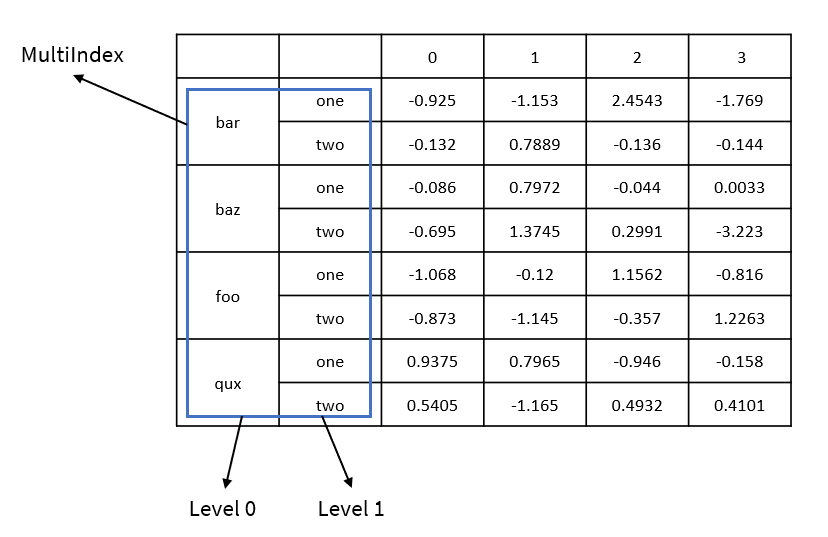
以下图为例,这里有两个索引级别,level 0 表示第一个索引级别,level 1 表示第二个索引级别。组合各个索引级别上的标签则可以构成一个索引项,例如 (‘bar’, ‘one’)、(‘foo’, ‘two’) 等。
基本属性
层次化索引的类型是 pandas.MultiIndex,它继承自 pandas.Index,有如下一些基本属性:
- names: 索引中各级别的名称,各级别名称的默认值是 None。
- levels: 标签列表,表示各级别的唯一标签。在上面的例子中,第一个级别有 ‘bar’、’baz’、’foo’、’qux’ 4 种标签,第二个级别只有 ‘one’ 和 ‘two’ 两种标签,因此 levels 的值是 [[‘bar’, ‘baz’, ‘foo’, ‘qux’], [‘one’, ‘two’]]。
- codes: 编码列表,表示索引各级别的编码值,编码值是一个整数,代表在标签列表中的位置,和 levels 配合生效。例如第一个级别的标签列表为 [‘bar’, ‘baz’, ‘foo’, ‘qux’],那么编码列表 [0, 0, 1, 1, 2, 2, 3, 3] 代表这个界别的索引标签为 [‘bar’, ‘bar’, ‘baz’, ‘baz’, ‘foo’, ‘foo’, ‘qux’, ‘qux’]。
- nlevels: 索引的总级别数。
- levshape: 索引中各级别标签的数目。
1 | In [1]: arrays = [['bar', 'bar', 'baz', 'baz', 'foo', 'foo', 'qux', 'qux'], |
构造函数
有多种创建 MultiIndex 的方式,分别包括:
- MultiIndex.from_arrays():通过标签数组创建层次化索引,每个数组代表一个索引级别上的标签。
- MultiIndex.from_tuples():通过元组列表创建层次化索引,每个元组代表一个索引项,即当前索引项在各个索引级别上的标签值。
- MultiIndex.from_product():通过各级别标签的笛卡尔积创建层次化索引。
- MultiIndex.from_frame():通过 DataFrame 对象创建层次化索引。
这些方法都可以接受一个 names 参数来指定索引各级别的名字,如不指定,则为默认值 None。
通过数组列表创建时,要求各数组的长度一致:
1 | In [1]: arrays = [['bar', 'bar', 'baz', 'baz', 'foo', 'foo', 'qux', 'qux'], |
也可以通过元组列表创建,元组列表可以非常直观地查看各索引项:
1 | In [1]: tuples = list(zip(*arrays)) |
from_product() 方法则会计算标签数组的笛卡尔积作为最终的索引项,例如一个 4 维数组和一个 2 维数组会产生 4 * 2 = 8 个索引项:
1 | In [1]: iterables = [['bar', 'baz', 'foo', 'qux'], ['one', 'two']] |
还可以将 DataFrame 直接转成 MultiIndex,每一列代表索引的一个级别,如果没有显式地设置 names 参数,则默认使用列名作为各级别名称:
1 | In [1]: df = pd.DataFrame([['bar', 'one'], ['bar', 'two'], |
创建带层次化索引的 Series/DataFrame
创建带层次化索引的 Series 和 DataFrame 非常简单,只需要将 MultiIndex 类型或对应的标签数组列表传入 index 参数即可:
1 | In [1]: arrays = [['bar', 'bar', 'baz', 'baz', 'foo', 'foo', 'qux', 'qux'], |
层次化所以不仅可以用于行索引,也可以用于列索引:
1 | In [1]: df = pd.DataFrame(np.random.randn(3, 8), index=['A', 'B', 'C'], columns=index) |
值得注意的是,如果传入的是元组列表(上面讲到的第二种构造层次化索引的方式),pandas 并不会自动将其解析为层次化索引,而是将整个元组当作一个索引级别。例如在下面的例子中,只有一个索引级别:
1 | In [1]: s = pd.Series(np.random.randn(8), index=tuples) |
检索层次化索引
和普通索引一样,层次化索引可以通过 iloc 方法进行基于位置的检索、通过 loc 方法进行基于轴标签的检索。其中 loc 方法的输入参数略有不同,需要用标签元组来替代单个轴标签:
1 | In [1]: df = df.T |
同时对行、列进行索引的方法也类似:
1 | In [1]: df.loc[('bar', 'two'), 'A'] |
层次化索引的一个重要特性就是部分索引,即只提供索引的部分标签,选取包含该标签的全部层次化索引:
1 | In [1]: df.loc[('bar',)] |
进行部分索引时,可以使用简略的写法,效果是一样的:
1 | In [1]: df.loc['bar'] |
索引运算符 [] 也支持简单的部分索引:
1 | In [1]: df = df.T |