Pandas 数据集合并(1)
Pandas 提供了多种工具来帮助我们方便地进行数据集合并:
- pandas.concat 方法可以沿着一条轴将多个对象堆叠到一起。
- pandas.merge 方法可以根据一个或多个键将不同 DataFrame 中的行连接起来,它实现的就是 SQL 或其他关系型数据库的 join 操作。
- 实例方法 combine_first 可以将重复数据拼接在一起,用一个对象中的值填充另一个对象中的缺失值。
pandas.concat 方法
concat 方法是 pandas 命名空间下的一个方法,它可以将多个数据集(Series 或 DataFrame)沿着某个轴方向连接,并且在其它轴方向上进行集合操作(并集或交集)。
1 | pd.concat(objs, axis=0, join='outer', ignore_index=False, keys=None, |
- objs: 参与连接的 pandas 对象(可以是 Series 或 DataFrame 对象)的列表或字典。如果是对象字典,则字典的键与下面的 keys 效果类似。
- axis: 指明连接的轴向,默认为 0,即沿着行方向合并。
- join: “inner” 或 “outer”,默认为 “outer”。指明其他轴(除了连接轴之外的轴)上的轴标签是按照交集(inner)还是并集(outer)进行合并。
- ignore_index: 不保留连接轴上的索引,产生一组新索引 0, 1, 2, …, n - 1。当待连接的数据集索引没有实际意义时,可以设置此参数。
- keys: 与连接对象有关,用于形成连接轴向上的层次化索引。可以是任意值的列表或数组、元组数组、数组列表(如果将 levels 设置成多级数组的话)。
- levels: 指定用作层次化索引各级别上的索引,如果设置了 keys 的话。
- names: 用于创建分层级别的名称,如果设置了 keys 和(或) levels 的话。
- verify_integrity: 检查结果对象新轴上的重复情况,如果发现则引发异常。默认为 False 允许重复。
- copy: 默认为 True,如果设置为 False,则不会进行不必要的数据复制。
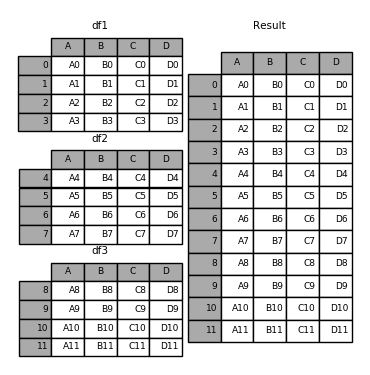
下面是一个简单的例子,将三个 DataFrame 沿着行进行合并:
1 | In [1]: df1 = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'], |
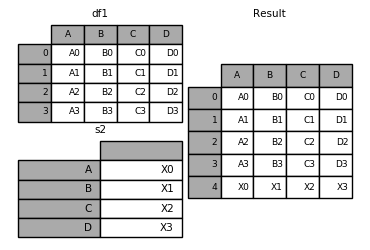
如果输入的是 Series 对象列表,此时 Series 会被转化成对应的 DataFrame,并使用 Series 的名字作为 DataFrame 的列名。对于没有名字的 Series,则默认使用整数序列以此编号:
1 | In [1]: s3 = pd.Series([0, 1, 2, 3], name='foo') |
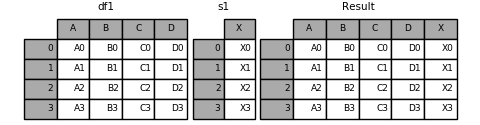
也可以在输入列表中混合使用 Series 和 DataFrame 对象:
1 | In [1]: s1 = pd.Series(['X0', 'X1', 'X2', 'X3'], name='X') |
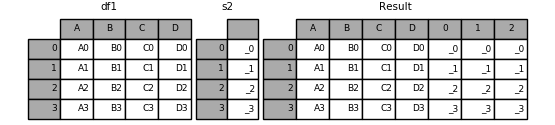
没有名字的 Series 同样会自动编号:
1 | In [1]: s2 = pd.Series(['_0', '_1', '_2', '_3']) |
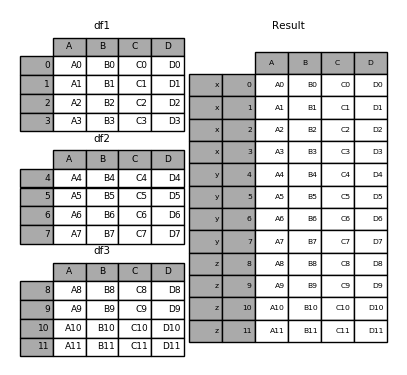
还可以输入对象字典,此时会生成层次化索引,字典的键变成索引的第一级,输入对象的原始索引变成索引的第二级:
1 | In [1]: result = pd.concat({'x': df1, 'y': df2, 'z': df3}) |
融合了 Series 和 DataFrame 对象的字典具有同样的效果:
1 | In [1]: result = pd.concat({'x': df1, 'y': s1, 'z': s2}, axis=1) |
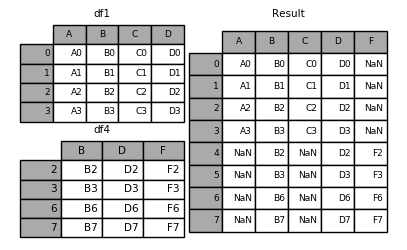
设置 ignore_index 为 True 可以忽略掉原始的轴标签,产生一组从 0 开始的新索引,这也是一个常用操作。
1 | In [1]: result = pd.concat([df1, df4], ignore_index=True) |
keys 参数
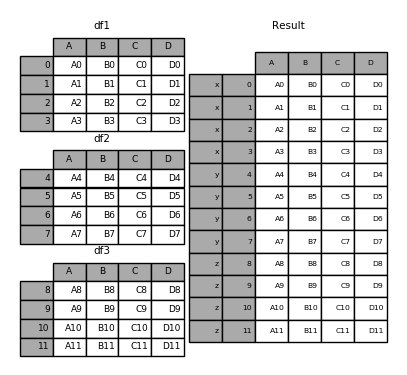
设置 keys 参数可以形成连接轴上的层次化索引,和对象字典效果一致:
1 | In [1]: result = pd.concat([df1, df2, df3], keys=['x, 'y', 'z']) |
通过部分索引可以实现数据源的筛选:
1 | In [1]: result.loc['y'] |
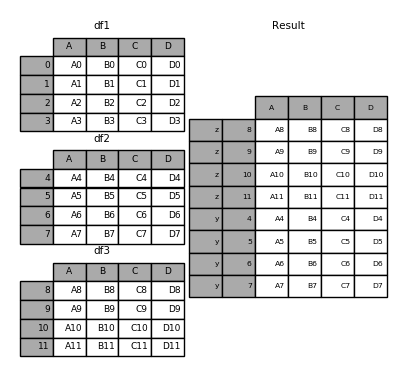
输入对象字典的同时设置 keys,可以只连接指定 key 对应的数据对象:
1 | In [1]: result = pd.concat({'x': df1, 'y': df2, 'z': df3}, keys=['y', 'z']) |
特别的,如果数据集都是 Series,那么 keys 会覆盖 Series 名字:
1 | In [1]: s3 = pd.Series([0, 1, 2, 3], name='foo') |
其他轴上的集合操作
在进行数据的合并时,不同 DataFrame 在非连接轴上的轴标签可能不完全相同,我们可以通过设置 join 参数来决定如何处理:
- join=’outer’:输出这些轴标签的并集,这是默认的方式,因为它不会带来信息丢失。
- join=’inner’:输出这些轴标签的交集,会损失部分信息。
1 | In [1]: df4 = pd.DataFrame({'B': ['B2', 'B3', 'B6', 'B7'], |
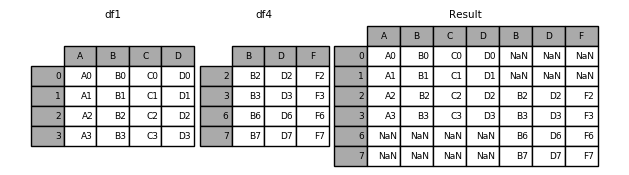
这里由于是在列上进行合并,因此 df1 的 4 列和 df2 的 3 列合并成 7 列,而在行方向上,[0, 1, 2, 3] 和 [2, 3, 6, 7] 的交集是 [0, 1, 2, 3, 6, 7],并集则是 [2, 3]。
1 | In [1]: result = pd.concat([df1, df4], axis=1, join='inner') |

索引设置
如果想要自己设置层次化索引的信息,则可以综合使用 keys、levels 和 names 参数来实现:
1 | In [1]: result = pd.concat({'x': df1, 'y': df2, 'z': df3}, |
append 方法
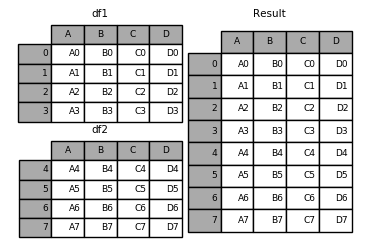
pandas.concat 方法有一个简化的版本,即 Series 或 DataFrame 实例对象的 append 方法。但是 append 方法只能沿着 axis=0 的轴进行合并,即沿着行进行数据合并,列标签采取并集的方式(对应 concat 方法中的 join=’outer’)处理:
1 | In[1]: result = df1.append(df2) |
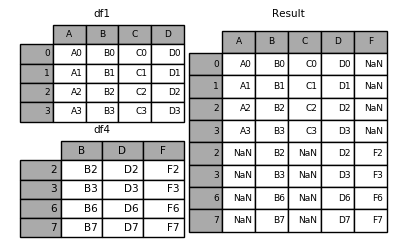
1 | In[1]: result = df1.append(df4) |
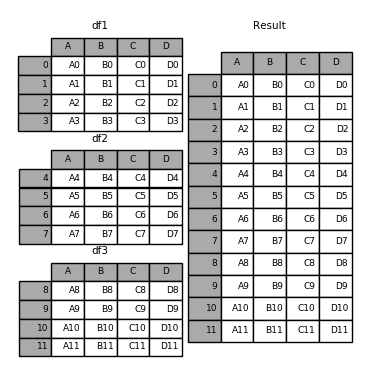
append 方法可以同时接受多个待合并的数据集:
1 | In[1]: result = df1.append([df2, df3]) |
还可以将向 DataFrame 中添加 Series 来增加新的行。需要注意的是,如果传入的 Series 对象没有名字,那么一定要设置 ignore_index=True,否则会抛出异常:
1 | In[1]: s2 = pd.Series(['X0', 'X1', 'X2', 'X3'], index=['A', 'B', 'C', 'D']) |